AI-Driven Development (AIDD) Without the Hype
What Actually Changes When AI Writes More of Your Code
This post is something I wish someone had spelled out when I was getting my hands dirty again; how to do AI-Driven Development (AIDD) in a way that actually holds up. I’d recently moved back to an individual contributor role after several years as a technical manager, and the day-to-day of writing and reviewing code had shifted more than I’d fully absorbed as a leader. Completion, prompts, and agentic flows aren’t additive tweaks; they change where effort goes and where the risks show up.
AIDD Spectrum
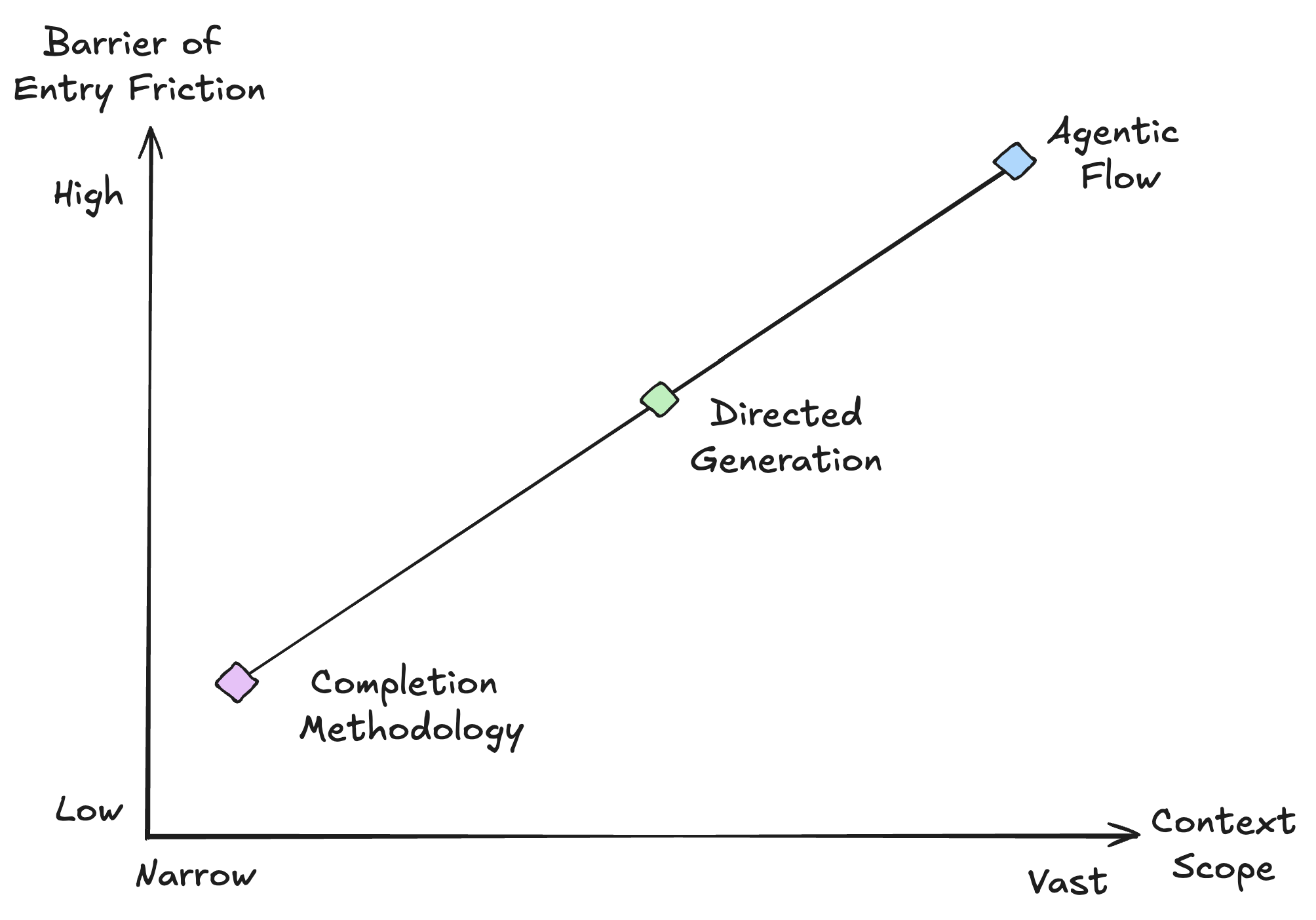
At one end lies completion - in which the model suggests the next token or line within a visible file. At the other lies agentic flow - where the model reasons over a task, invokes tools (read file, run tests, search codebase), and iterates. Completion offers low entry point friction but narrow context, while agentic flow offers breadth at the cost of designing specification, tools, and termination conditions. In practice, many teams operate in the middle (which I'm labeling directed generation) with targeted prompts supplied with structured context (e.g., the relevant file, the rule that fired, and the snippet to fix). That middle ground is where most of the interesting engineering decisions live.
Where the Work Shifts

In traditional development, the engineer retains the full chain in mind: requirements, design, implementation, tests, and deployment. AIDD compresses the implementation phase and more effort goes into framing the task, reviewing output, and integrating it, and less into typing boilerplate or hand-writing every branch. The throughput gain is real, but only if you treat the output as a candidate - not as ground truth.
It follows that feedback loops must scale with that throughput. Linting and tests catch many defects; they do not reliably catch wrong abstractions or subtle security flaws. AIDD therefore favors earlier and more automated feedback such as static analysis, security checks, and tool-enabled code review that is capable of higher volume. Teams that adopt AIDD successfully tend to already have strong quality and security practices; those that do not often find that increased speed merely increases the rate at which defective code is produced.
Security in the Loop
When AI generates more code, both attack surface and dependency surface grow. The team is not only producing more code locally but accepting more from a model that has no representation of the organization's threat model or compliance requirements. Security therefore cannot be relegated to a single gate at the end of the pipeline; it must be embedded in the loop: secure defaults, automated checks that execute at the point of authoring, and triage that separates actionable findings from noise so that developers do not normalize ignoring alerts.
At scale this becomes an AppSec and platform concern. Two classes of mechanism are necessary. First, deterministic guardrails, or rules that do not depend on a model, such as formatting, prohibited APIs, banned http verbs, required patterns, and more. These are typically implemented as custom linter rules, SAST rule packs, or pre-commit hooks so that they run on every change regardless of author. For example, a rule that blocks obvious misconfigurations before any AI-generated code is considered:
12345# Example: deterministic guardrail (conceptually) - id: no-eval-in-user-input pattern: "eval(${...userInput...})" severity: error message: "Never eval user-controlled input; use a safe parser or allowlist."
Second, context-aware analysis, where the model (or a system that invokes one) is given the finding, the surrounding code, and codebase conventions, and proposes a fix plan. The distinction is one of scope. A scanner reports “SQL injection risk at line 47.” A context-aware system can produce “this is a parameterized query codebase; here is the fix in the same style, and the tests that must pass.”
That requires real context - the file contents, call graph, and a structured finding. SARIF (Static Analysis Results Interchange Format) is the standard for this: tool-agnostic, with locations, code flows, and fix hints baked in.
123456{ “ruleId”: “java/sql-injection”, “message”: { “text”: “Parameterize this query.” }, “locations”: [{ “physicalLocation”: { “artifactLocation”: { “uri”: “src/dao/UserDao.java” }, “region”: { “startLine”: 47 } } }], “codeFlows”: [{ “threadFlows”: [{ “locations”: [...] }] }] }
That payload, together with the file and optionally the repository’s style guide, gives the model enough to produce a fix that actually fits the project. The result should preserve behavior and match existing patterns - a parameterized query in the same style as the rest of the DAO:
1234567// Before: concatenated input → SQL injection String sql = "SELECT * FROM users WHERE email = '" + userInput + "'"; // After: parameterized → same API, safe String sql = "SELECT * FROM users WHERE email = ?"; PreparedStatement stmt = conn.prepareStatement(sql); stmt.setString(1, userInput);
Without that context, the model produces generic patches. They might not compile. They might bypass existing helpers. And if the patch doesn't match the team's standards, you're trading a vulnerability for tech debt.
Where AIDD Helps - And Where It Does Not
AIDD is effective when the problem is well-scoped and success criteria are verifiable. Boilerplate, repetitive refactors, tests derived from specifications, and routine migrations are suitable; so is exploratory work (“show three ways to achieve X” or “explain this code and suggest a simplification”) provided the output is checked against a defined acceptance criteria. The model functions as a useful assistant when kept within a bounded task and when every output is validated.
A recurring pattern is to make input and acceptance explicit in the prompt so that the model and the human share the same contract:
123456789101112You are fixing a single finding. Do not change unrelated code. Input: - Rule: java/sql-injection (parameterize query) - File: UserDao.java, lines 45–52 - Code: [pasted snippet] Constraints: - Use the existing PreparedStatement pattern used elsewhere in this file. - Output only the changed method body, no explanation. Acceptance Criteria: The result must compile and the existing test UserDaoTest#findByEmail must pass.
The suggested change is run through the compiler and the test suite; if either fails, the change is rejected. That constitutes a minimal but real feedback loop. Adding further checks (SAST on the diff, SCA, code review) yields AIDD with guardrails rather than reliance on hope.
AIDD is a poor fit when the task is underspecified, highly domain-specific, or safety-critical in ways that cannot be validated by tests alone. Architecture decisions, cross-system contracts, and anything that touches data classification or compliance require a human in the loop who retains responsibility for the outcome. Effective practitioners maintain a strict boundary where they use AI to expand options and accelerate mechanical work, and reserve human judgment for what is shipped.
On Writing Useful Specifications
The quality of specifications becomes more critical under AIDD because the model often treats the spec as the primary definition of correctness. Ambiguous or underspecified requirements propagate into generated code and tests; clear, verifiable specs constrain the output space and make acceptance checks possible.
Principles. A specification suitable for both human and machine consumption should be (1) unambiguous—each requirement admits a single interpretation; (2) verifiable—there exists a mechanical check (test, static analysis, or review checklist) that can confirm satisfaction; and (3) scoped—one level of abstraction per document or section, so that “what” is not conflated with “how.” Implicit assumptions should be made explicit or removed.
Structure. Useful forms include: preconditions and postconditions for an operation; invariants that must hold before and after; or a Given/When/Then (or equivalent) style that binds inputs, actions, and observable outcomes. The goal is to make the contract testable. For example, an API contract might specify the shape of the request and response, error codes, and idempotency behavior, so that both a human and a model can generate a client or test that either satisfies or violates the spec.
Anti-patterns. Vague acceptance criteria (“should be fast,” “handle errors gracefully”) are not verifiable. Specs that mix policy (“only admins may delete”) with implementation detail (“call AuthService.checkRole”) blur the boundary between what to build and how. Specs that are scattered across tickets, comments, and tribal knowledge cannot be supplied to a model as a single context; a single source of truth, versioned and machine-readable where possible, reduces drift.
The following contrast illustrates the difference. A weak spec leaves room for incompatible implementations:
123# Weak: underspecified - Endpoint returns user data. - Invalid IDs are handled appropriately.
A stronger spec gives the model and the reviewer something to check against:
123456# Strong: verifiable contract - GET /users/:id - 200: body is JSON object with fields { id, email, createdAt }; id matches path param. - 404: when no user exists for id; body is { "error": "NOT_FOUND", "requestId": "" }. - 400: when id is not a valid UUID format; body is { "error": "INVALID_ID", "requestId": " " }. - No other response codes. All responses include Content-Type: application/json.
With the stronger spec, one can write tests (or prompt a model to write tests) that pass or fail unambiguously; the same is not true of the weak spec. Investing in specification quality is therefore a multiplier for AIDD: it improves both human reasoning and machine-generated code and tests.
What Good Looks Like
Effective AIDD exhibits three properties: (1) clear ownership of prompts and context (the team decides what the model sees); (2) automated checks on every change (tests, SAST, SCA, and ideally fix validation); and (3) a culture that treats AI output as draft material. The pipeline is the product: a fix proposed by the model should pass the same gates as a human-written patch.
Conceptually, that pipeline takes the following form:
12[Scanner / finding] → [Context assembly: file, rule, codeflow] → [Model: propose fix] → [Apply patch] → [Build] → [Unit tests] → [SAST on diff] → [Human review or auto-merge]
Context assembly is the step that is often underinvested in. One constructs a single payload the model can reason over—e.g., the finding (SARIF or equivalent), the affected file(s), and a short style hint:
12345{ "finding": { "ruleId": "java/sql-injection", "message": "...", "locations": [...] }, "file": { "path": "src/dao/UserDao.java", "contents": "..." }, "style": "Use PreparedStatement; see findById() in this file." }
If any step fails, the change is not shipped. The expensive part isn't the model call - it's the context assembly and the validation. Teams that skip validation end up with “AI wrote it” as a post hoc excuse for a CVE. Teams that invest in the pipeline get leverage without the regret. I've spent the last several years building systems like this between AWS and Pixee, where automation and AI integrate into the development process rather than block it.
AIDD means more code, faster. That's the point. But more code also means more findings, more noise, and more review fatigue... and as we covered above, speed without validation just produces defects at a higher rate. At Pixee, that's the problem we're working on: integrating with existing scanners, sorting through their findings, and separating the signal from the noise. Roughly 88% of what scanners flag turns out to be false positives. Of the true positives that remain, our automated fix merge rate across 100,000+ fixes sits at 76% - meaning three out of four times, the developer looks at the proposed fix and thinks "that's exactly the change I'd make" and hits merge. That's the bar: not just finding the problem, but proposing a fix that a human trusts enough to ship.
The broader point is this: AIDD only scales as far as your ability to keep releases unblocked. You can generate code faster than ever, but if findings pile up, reviews bottleneck, and fixes sit in a queue, the speed is an illusion. Whether it's Pixee or another tool in that space, you need something in the pipeline that triages, fixes, and clears the path. Everything in this post - the AIDD spectrum, feedback loops, spec quality - will help you write better AI-driven code. But that's only half the equation. Without tooling to keep releases moving, all that effort just shifts the bottleneck from writing code to shipping it.