Write Claude Skills. Don't Depend on Them.
Why Skill Repos Struggle Where SaaS Succeeds
There is a pattern in security automation that repeats itself. Someone writes a smart script or skill that does something valuable, puts it in a shared repo, and schedules it to run daily. Other people see it, write their own, commit them alongside the first one. The repo grows. The automations run. Then something breaks: an endpoint changes, a library gets deprecated, a permission gets rotated. And suddenly no one knows who owns it.
I lived this at AWS. The scripts were Python, they were large, and some of them were running proactive security automations across the organization. When an author moved off the AppSec team or left the company, that script became my team's by default. I wasn't the author. I didn't know all the edge cases. But someone had to own it, and that someone ended up being me.
The more important pattern I noticed was not the maintenance burden itself. It was what the maintenance burden did to the people writing the automation. Over time, engineers became reluctant to write new automation scripts because every script they wrote was one more thing they'd have to own while also doing their actual jobs. The incentive structure was backwards: write more automation, take on more technical debt. So people wrote less.
Why Skill Repos Hit the Same Wall
Claude Code skills are genuinely useful. They let engineers build reusable, composable automations on top of the model. The experience of writing a skill, seeing it work, and sharing it with a team is satisfying. I am not arguing against writing LLM skills.
What I am arguing is that depending on a shared skills repo for anything production-critical runs into the same ownership and maintenance dynamics that killed the Python script libraries before them.
The problem is not the technology. It is the model of shared ownership without real accountability. When a skill breaks because of an API change, a prompt format update, or a new model behavior, who patches it? If the answer is "whoever is on call" or "whoever has time," the skill is already in the graveyard. It just has not stopped running yet.
The Token Math Does Not Work Out
SaaS products built around LLMs invest heavily in prompt caching. Cached tokens at Anthropic pricing cost a fraction of fresh input tokens. A product that caches its system prompts, context, and common patterns across thousands of requests can reduce token spend by 60-80%. That economics shapes the product: it means a SaaS provider can afford to invest in rich context, detailed reasoning chains, and multiple model calls because the costs spread across the user base and get optimized over time.
A skill in a shared repo does not have that. Every invocation is effectively fresh. There is no infrastructure for caching, no cost optimization across runs, and no one whose job it is to reduce the token footprint. The cost of running skills grows linearly with usage, and the incentive to optimize it does not exist the same way it does inside a commercial product.
Models Change, and That Changes Everything
One assumption that skill repos make implicitly is that the underlying model stays consistent. It does not. Here is an example:
When Anthropic released Claude Opus 4.7, teams running automations on Claude Sonnet 4.6 found that outputs changed in ways they did not anticipate. Not always worse, often better, but different. A comparison of the two found roughly 43% more verbose output across analysis tasks, with code review comments coming in 68% more verbose. If your skill was tuned to produce a specific format, or to follow a reasoning pattern that matched how 4.6 responded, upgrading the model underneath it without re-validating is a gamble. Verbosity alone can break downstream parsing, tone expectations, or structured output contracts.
Anthropic themselves have documented this kind of silent shift. An April 2026 postmortem described a bug in thinking block management that caused the API to clear reasoning history mid-session:
"forgetfulness, repetition, and odd tool choices"
That kind of behavioral change does not announce itself. It shows up as degraded output, and if no one is watching, it keeps degrading.
SaaS products have teams that handle model transitions: they benchmark outputs before and after, run regression suites, and gate rollouts until the new model matches or exceeds the old behavior on the metrics that matter. A skill repo typically has none of that. The author updates the model version, the outputs drift, and no one notices until something downstream breaks.
Unless you are actively benchmarking your skills against defined acceptance criteria on every model update, you are flying without instruments.
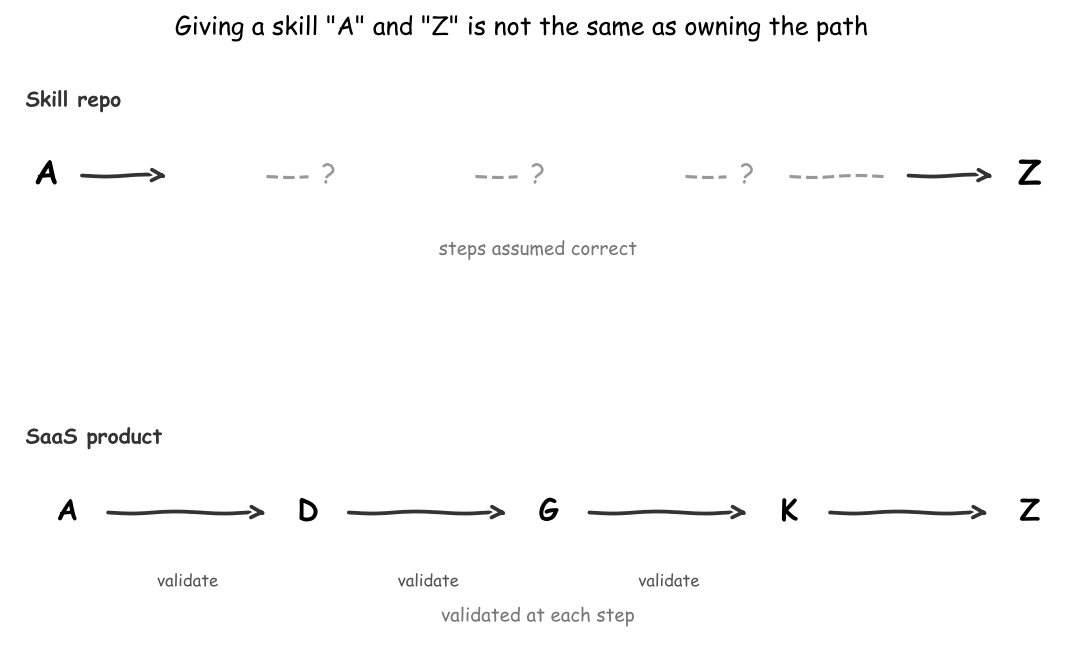
The A-to-Z Problem
Giving a skill a starting point and an ending point does not mean the steps in between will be right.
You can hand an LLM a task and say: start here, end there. The model will get from A to Z. But whether it got B, C, D, and E right along the way is a different question. In high-stakes workflows, the path matters as much as the destination.
A well-engineered SaaS product handles this differently. Instead of asking the model to traverse the whole alphabet in one shot, the product breaks the problem into bounded sub-tasks: get from A to D, validate, then from D to G, validate again. Each segment has defined inputs, expected outputs, and a check that confirms the work before handing off to the next step. The model is a participant in a structured process, not a freeform agent handed an endpoint.
That kind of orchestration is what separates a skill from a product. Skills are useful for well-scoped tasks. Products invest in the scaffolding that makes complex multi-step workflows reliable.
Security Teams Are Not Going to Trust a Skill Repo
This is the clearest version of the argument: security teams will still require security actions.
A Claude skill that runs a proactive security automation is interesting. But when a security team needs to demonstrate that a control is in place, they need something auditable, versioned, and owned. A skill in a shared repo does not come with SLAs, support, or accountability. It does not have a vendor who can explain why an output looked the way it did on a specific date.
At Pixee, we have thought carefully about what it means for automated security fixes to be trustworthy enough to ship. The answer is not a prompt. It is a combination of context assembly, deterministic validation, regression testing, scanner integrations maintained over time, and a fix merge rate built on thousands of production examples. Engineers reviewing a proposed fix need to be able to look at it and say "this is exactly what I would do." Getting there required years of engineering, not a well-written skill.
Teams will want to experiment with skills, and they should. But a security program that depends on an unowned skill repo for production controls has a gap in it.
What Skills Are Good For
None of this means you should not write skills. You should. They are excellent for:
- Prototyping - Validate an automation idea before deciding whether to invest in a real product.
- Bounded, low-stakes tasks - Where a wrong output is noticeable and correctable before it causes damage.
- Individual workflows - Accelerating work that does not require the reliability of a production system.
- Learning - Understanding how to think about LLM-based automation so you can evaluate SaaS products intelligently.
The limit is the production dependency. Once a skill becomes load-bearing, it needs the infrastructure that SaaS products provide: ownership, caching, model management, benchmarking, and accountability. That infrastructure is not free to build, and it is not free to maintain. It is what you are buying when you choose a product over a repo.
TL;DR - Write the skills. Learn from them. Just be honest about what they are.